#!/usr/bin/env bash
#
# Run fastp on the raw fastq files
#
# ----------------------------------------------------------------------------
set -Eeou pipefail
FQ=/path/to/00_fastq # Directory containing raw fastq files
SAMPLES=sample-names.txt # A text file listing basenames of fastq files
OUT=/path/to/put/01_fastp # Where to save the fastp results
THREADS=8
mkdir -p $OUT
for SAMPLE in $(cat $SAMPLES)
do
fastp -i $FQ/${SAMPLE}_R1.fq.gz \
-I $FQ/${SAMPLE}_R2.fq.gz \
-o $OUT/${SAMPLE}.trimmed.1.fq.gz \
-O $OUT/${SAMPLE}.trimmed.2.fq.gz \
-h $OUT/${SAMPLE}.fastp.html \
-j $OUT/${SAMPLE}.fastp.json \
--detect_adapter_for_pe \
-w $THREADS
doneDifferential Expression Analysis
This vignette outlines some common steps for RNA-seq analysis highlighting functions present in the coriell package. To illustrate some of the analysis steps I will borrow examples and data from the rnaseqGene and RNAseq123 Bioconductor workflows. Please check out the above workflows for more details regarding RNA-seq analysis.
This vignette contains my opinionated notes on performing RNA-seq analyses. I try to closely follow best practices from package authors but if any information is out of date or incorrect, please let me know.
Overview
Differential gene expression analysis using RNA-seq typically consists of several steps:
- Quality control of the fastq files with a tool like FastQC or fastp and more recently, RustQC
- Alignment of fastq files to a reference genome using a splice-aware aligner like STAR or transcript quantification using a pseudoaligner like Salmon.
- If using a genome aligner, read counting with Rsubread::featureCounts or HTSeq count to generate gene counts. If using a transcript aligner, importing gene-level counts using the appropriate offsets with tximport or tximeta
- Quality control plots of the count level data including PCA, heatmaps, relative-log expression boxplots, density plots of count distributions, and parallel coordinate plots of libraries. Additionally, check the assumptions of global scaling normalization.
- Differential expression testing on the raw counts using edgeR, DESeq2, baySeq, or limma::voom
- Creation of results plots such as volcano or MA plots.
- Gene ontology analysis of interesting genes.
- Gene set enrichment analysis.
Workflow managers
Most of the above processing steps can (and should) be orchestrated using a workflow manager like Snakemake or Nextflow. Below, I demonstrate example processing steps using simple Bash scripts for simplicity and illustrative purposes.
Quality Control
fastp has quickly become my favorite tool for QC’ing fastq files primarily because it is fast and produces nice looking output files that are also amenable to summarization with MultiQC. fastp can also perform adapter trimming on paired-end reads. I tend to fall in the camp that believes read quality trimming is not necessary for RNA-seq alignment. However, I have never experienced worse results after using the adapter trimming with fastp so I leave it be and just inspect the output carefully.
A simple bash script for running fastp over a set of fastq files might look something like this:
Where sample-names.txt is a simple text file with each basename like so:
Control1
Control2
Control3
Treatment1
Treatment2
Treatment3It is important to name the results files with *.fastp.{json|html} so that multiqc can recognize the extensions and combine the results automatically.
Alignment and Quantification
Salmon
I tend to perform quantification with Salmon to obtain transcript-level counts for each sample. A simple bash script for performing quantification with Salmon looks like:
#!/usr/bin/env bash
#
# Perform transcript quantification with Salmon
#
# ----------------------------------------------------------------------------
set -Eeou pipefail
SAMPLES=sample-names.txt # Same sample-names.txt file as above
IDX=/path/to/salmon-idx # Index used by Salmon
FQ=/path/to/01_fastp # Directory containing the fastp output
OUT=/path/to/02_quants # Where to save the Salmon results
THREADS=12
mkdir -p $OUT
for SAMPLE in $(cat $SAMPLES)
do
salmon quant \
-i $IDX \
-l A \
-1 $FQ/${SAMPLE}.trimmed.1.fq.gz \
-2 $FQ/${SAMPLE}.trimmed.2.fq.gz \
--gcBias \
--seqBias \
--threads $THREADS \
-o $OUT/${SAMPLE}_quants
doneI tend to always use the --gcBias and --seqBias flags as they don’t impair accuracy in the absence of biases (quantification just takes a little longer).
STAR
Sometimes I also need to produce genomic coordinates for alignments. For this purpose I tend to use STAR to generate BAM files as well as produce gene-level counts with it’s inbuilt HTSeq-count functionality. A simple bash script for running STAR might look like:
#!/usr/bin/env bash
#
# Align reads with STAR
#
# ----------------------------------------------------------------------------
set -Eeou pipefail
SAMPLES=sample-names.txt # Same sample-names.txt file as above
FQ=/path/to/01_fastp # Directory containing the fastp output
OUT=/path/to/03_STAR_outs # Where to save the STAR results
IDX=/path/to/STAR-idx # Index used by STAR for alignment
THREADS=24
mkdir -p $OUT
for SAMPLE in $(cat $SAMPLES)
do
STAR --runThreadN $THREADS \
--genomeDir $IDX \
--readFilesIn ${FQ}/${SAMPLE}.trimmed.1.fq.gz ${FQ}/${SAMPLE}.trimmed.2.fq.gz \
--readFilesCommand zcat \
--outFilterType BySJout \
--outFileNamePrefix ${OUT}/${SAMPLE}_ \
--alignSJoverhangMin 8 \
--alignSJDBoverhangMin 1 \
--outFilterMismatchNmax 999 \
--outFilterMismatchNoverReadLmax 0.04 \
--alignIntronMin 20 \
--alignIntronMax 1000000 \
--alignMatesGapMax 1000000 \
--outMultimapperOrder Random \
--outSAMtype BAM SortedByCoordinate \
--quantMode GeneCounts;
doneFor STAR I tend to use the ENCODE default parameters above for human samples and also output gene level counts using the --quantMode GeneCounts flag.
Generating a matrix of gene counts
The recommended methods for performing differential expression analysis implemented in edgeR, DESeq2, baySeq, and limma::voom all require raw count matrices as input data.
Importing transcript-level counts from Salmon
We use R to import the quant files into the active session. tximeta will download the appropriate metadata for the reference genome used and import the results as a SummarizedExperiment object. Check out the tutorial for working with SummarizedExperiment objects if you are unfamiliar with their structure.
The code below will create a data.frame mapping sample names to file paths containing quantification results. This data.frame is then used by tximeta to import Salmon quantification results at the transcript level (along with transcript annotations). Then, we use summarizeToGene() to summarize the tx counts to the gene level. Finally, we transform the SummarizedExperiment object to a DGEList for use in downstream analysis with edgeR
library(tximeta)
library(edgeR)
quant_files <- list.files(
path = "02_quants",
pattern = "quant.sf",
full.names = TRUE,
recursive = TRUE
)
# Extract samples names from filepaths
names(quant_files) <- gsub("02_quants", "", quant_files, fixed = TRUE)
names(quant_files) <- gsub(
"_quants/quant.sf",
"",
names(quant_files),
fixed = TRUE
)
# Create metadata for import
coldata <- data.frame(
names = names(quant_files),
files = quant_files,
group = factor(rep(c("Control", "Treatment"), each = 3))
)
# Import transcript counts with tximeta
se <- tximeta(coldata)
# Summarize tx counts to the gene-level
gse <- summarizeToGene(se, countsFromAbundance = "scaledTPM")
# Import into edgeR for downstream analysis
y <- SE2DGEList(gse)Importing gene counts from STAR
If you used STAR to generate counts with HTSeq-count then edgeR can directly import the results for downstream analysis like so:
library(edgeR)
# Specify the filepaths to gene counts from STAR
count_files <- list.files(
path = "03_STAR_outs",
pattern = "*.ReadsPerGene.out.tab",
full.names = TRUE
)
# Name the file with their sample names
names(count_files) <- gsub(".ReadsPerGene.out.tab", "", basename(count_files))
# Import HTSeq counts into a DGEList
y <- readDGE(
files = count_files,
columns = c(1, 2), # Gene name and 'unstranded' count columns
group = factor(rep(c("Control", "Treatment"), each = 3)),
labels = names(count_files)
)Counting reads with featureCounts()
Another (preferred) option for generating counts from BAM files is to use the function featureCounts() from the Rsubread R package. featureCounts() is very fast and has many options to control exactly how reads are counted. featureCounts() is also very general. For example, you can use featureCounts() to count reads over exons, introns, or arbitrary genomic ranges - it’s a very useful tool.
featureCounts() can use an inbuilt annotation or take a user supplied GTF file to count reads over. The inbuilt annotation (NCBI RefSeq) works particularly well with downstream functions implemented in edgeR. See ?Rsubread::featureCounts() for more information about using your own GTF file.
The resulting object can also be easily coerced to a DGEList for downstream analysis.
library(Rsubread)
# Specify the path to the BAM files produced by STAR
bam_files <- list.files(
path = "path/to/bam_files",
pattern = "*.bam$",
full.names = TRUE
)
# Optionally name the bam files
names(bam_files) <- gsub(".bam", "", basename(bam_files))
# Count reads over genes for a paired-end library
fc <- featureCounts(
files = bam_files,
annot.inbuilt = "hg38",
isPairedEnd = TRUE,
countReadPairs = TRUE,
nThreads = 12
)
# Coerce to DGEList for downstream analysis
y <- edgeR::featureCounts2DGEList(fc)Test data
We will use data from the airway package to illustrate differential expression analysis steps. Please see Section 2 of the rnaseqGene workflow for more information.
Below, we load the data from the airway package and use SE2DGEList to convert the object to a DGElist for use with edgeR.
library(airway)
library(edgeR)
# Load the SummarizedExperiment object
data(airway)
# Set the group levels
airway$group <- factor(airway$dex, levels = c("untrt", "trt"))
# Convert to a DGEList to be consistent with above steps
y <- SE2DGEList(airway)
# Reorder so that replicates from the same group are next to each other
# this will make this easier to visualize downstream
y <- y[, order(y$samples$group)]Library QC
Before we perform differential expression analysis it is important to explore the samples’ library distributions to ensure good quality before downstream analysis. There are several diagnostic plots we can use for this purpose implemented in the coriell package. However, first we must remove any features that have too low of counts for meaningful differential expression analysis. This can be achieved using edgeR::filterByExpr().
# Determine which genes have enough counts to keep around
keep <- filterByExpr(y)
# How many genes are kept?
table(keep)keep
FALSE TRUE
47751 15926 # Remove the unexpressed genes
y <- y[keep, , keep.lib.sizes = FALSE]At this stage it is often wise to perform library QC on the library size normalized counts. This will give us an idea about potential global expression differences and potential outliers before introducing normalization factors. I also like to check the same plots after applying normalization factors.
We can use edgeR to generate log2 counts-per-million values for the retained genes.
logcounts <- cpm(y, log = TRUE)Relative log-expression boxplots
The first diagnostic plot we can look at is a plot of the relative log expression values. RLE plots are good diagnostic tools for evaluating unwanted variation in libraries.
library(coriell)
plot_boxplot2(
logcounts,
y$samples,
fill_by = "group",
rle = TRUE,
show_outliers = FALSE,
plot_title = "Relative Log Expression",
y_label = "RLE"
)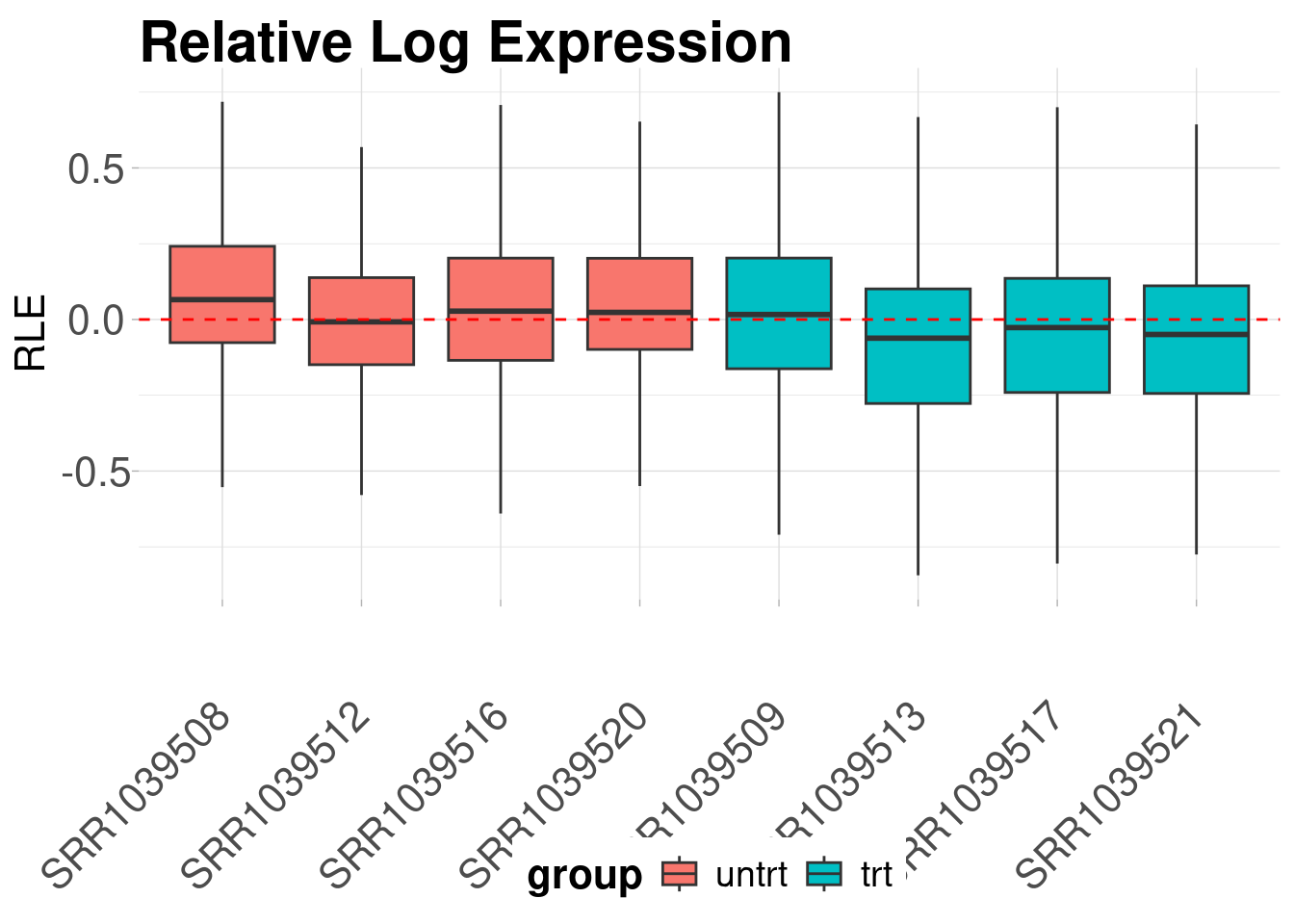
We can see from the above RLE plot that the samples are centered around zero and have mostly similar distributions. It is also clear that two of the samples, “SRR1039520” and “SRR1039521”, have slightly different distributions than the others.
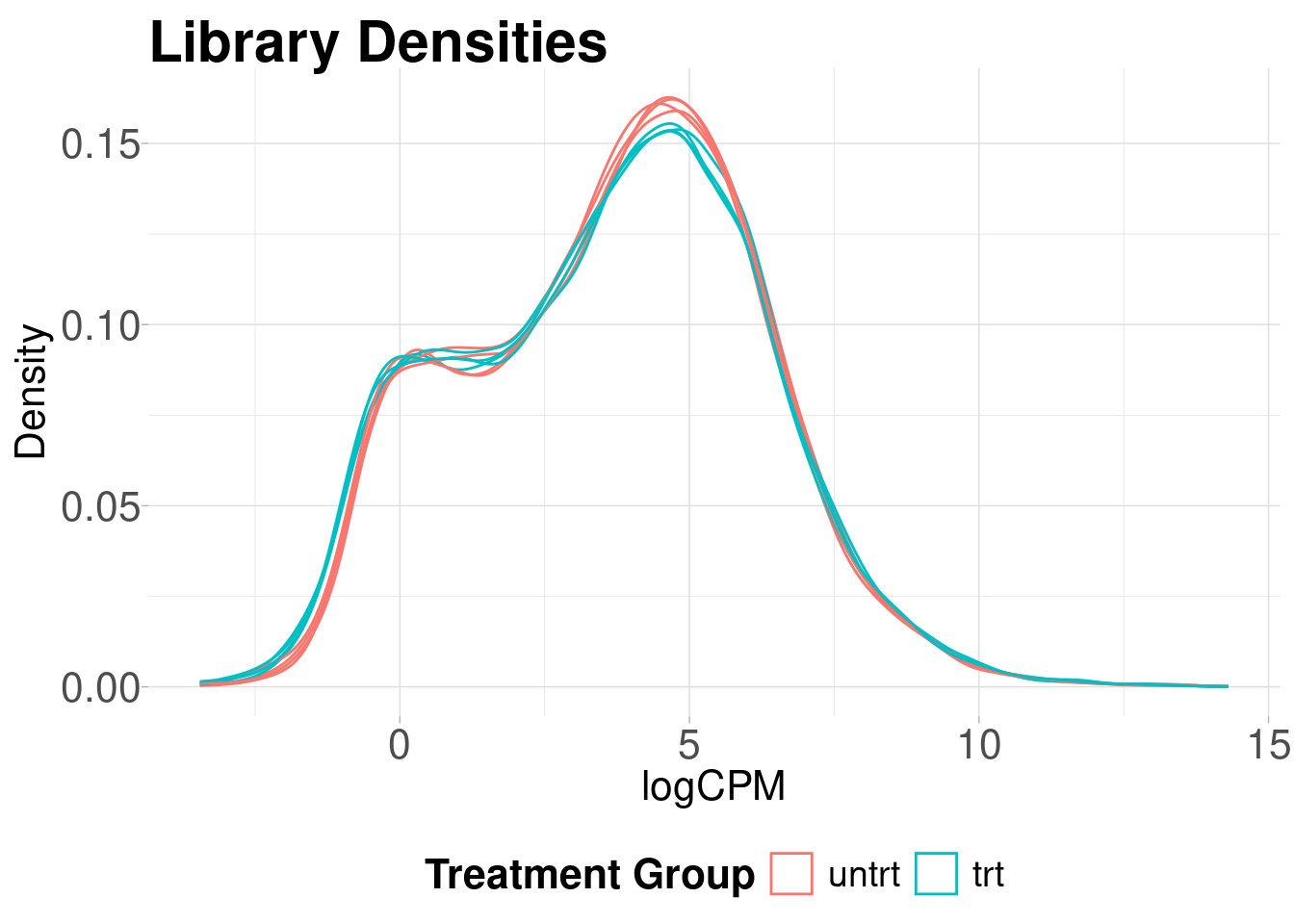
Library density plots
Library density plots show the density of reads corresponding to a particular magnitude of counts. Shifts of these curves should align with group differences and generally samples from the same group should have overlapping density curves
plot_density2(
logcounts,
y$samples,
col_by = "group",
plot_title = "Library Density",
x_label = "logCPM"
)
Sample vs Sample Distances
We can also calculate the euclidean distance between all pairs of samples and display this on a heatmap. Again, samples from the same group should show smaller distances than sample pairs from differing groups.
plot_dist(logcounts, metadata = y$samples[, "group", drop = FALSE])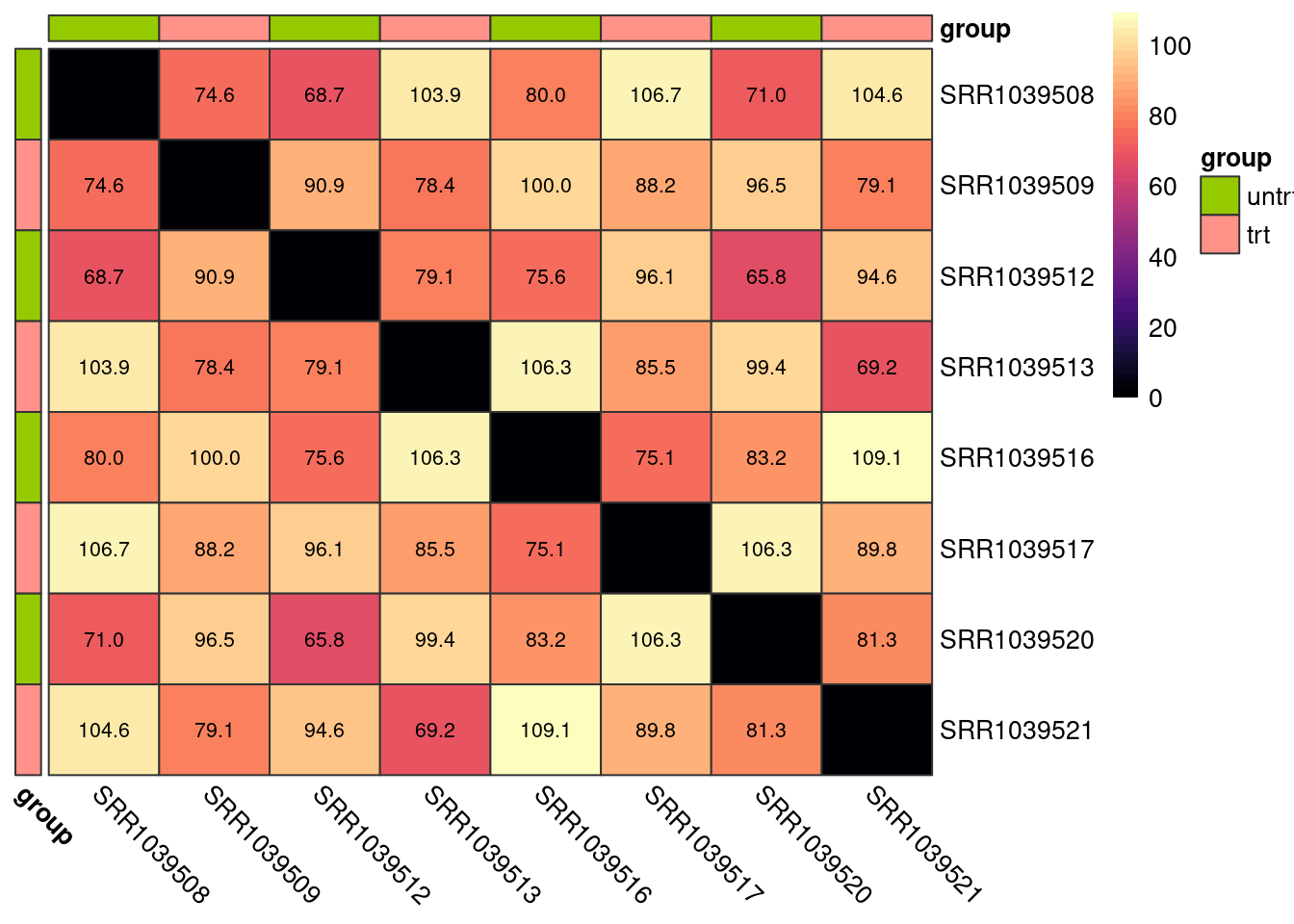
Parallel coordinates plot
Parallel coordinates plots are useful for giving you an idea of how the most variable genes change between treatment groups. These plots show the expression of each gene as a line on the y-axis traced between samples on the x-axis.
plot_parallel2(
logcounts,
plot_title = "10% Most Variable Genes",
y_label = "Scaled Expression"
)Removing 90% lowest variance features...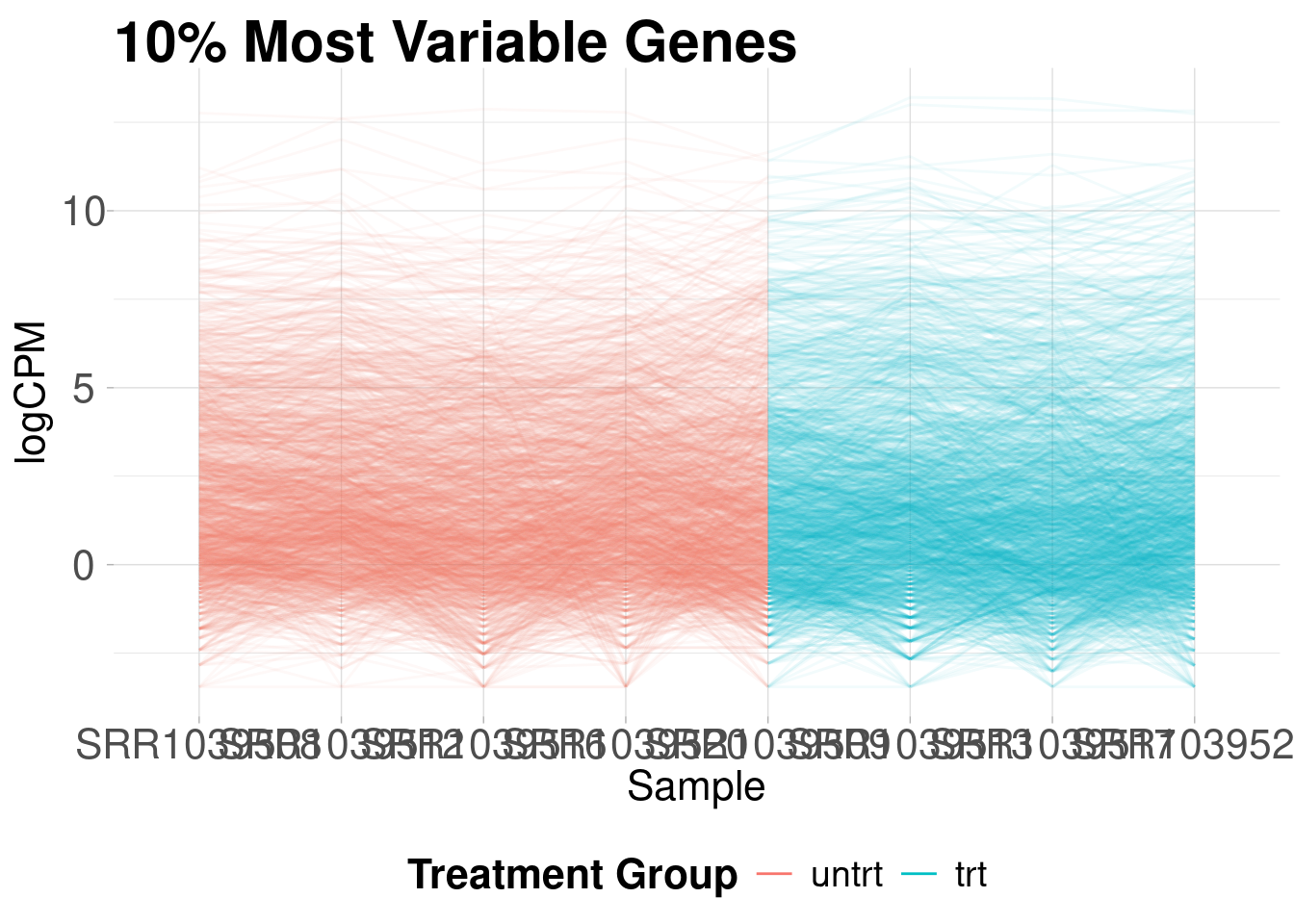
Correlations between samples
We can also plot the pairwise correlations between all samples. These plots can be useful for identifying technical replicates that deviate from the group
plot_cor_pairs(logcounts, cex_labels = 1)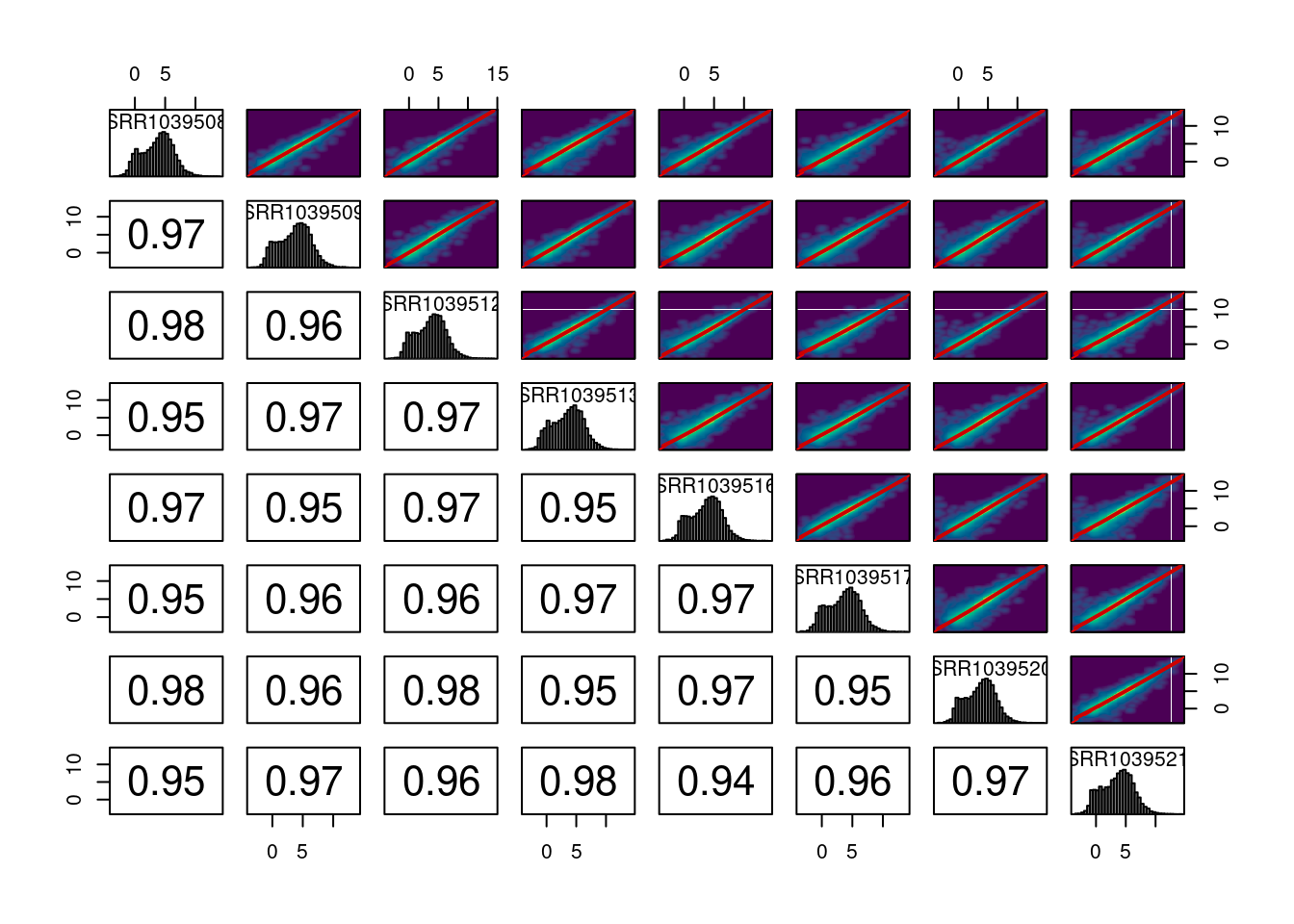
PCA
Principal components analysis is an unsupervised method for reducing the dimensionality of a dataset while maintaining its fundamental structure. PCA biplots can be used to examine sample groupings following PCA. These biplots can reveal overall patterns of expression as well as potential problematic samples prior to downstream analysis. For simple analyses we expect to see the ‘main’ effect primarily along the first component.
I like to use edgeR::plotMDS(y) for quickly computing and plotting principal components. For more complicated experiments I have also found UMAP (see coriell::UMAP()) to be useful for dimensionality reduction (although using UMAP is not without its problems for biologists).
# Set up the color palette to match the above plots
grp_pal <- hcl.colors(n = nlevels(y$samples$group), palette = "Dark 3")
names(grp_pal) <- levels(y$samples$group)
# Create the PCA plot by using 'gene.selection = "common"''
plotMDS(
logcounts,
pch = 16,
col = grp_pal[y$samples$group],
cex = 1.8,
gene.selection = "common"
)
legend("top", legend = levels(y$samples$group), col = grp_pal, pch = 16)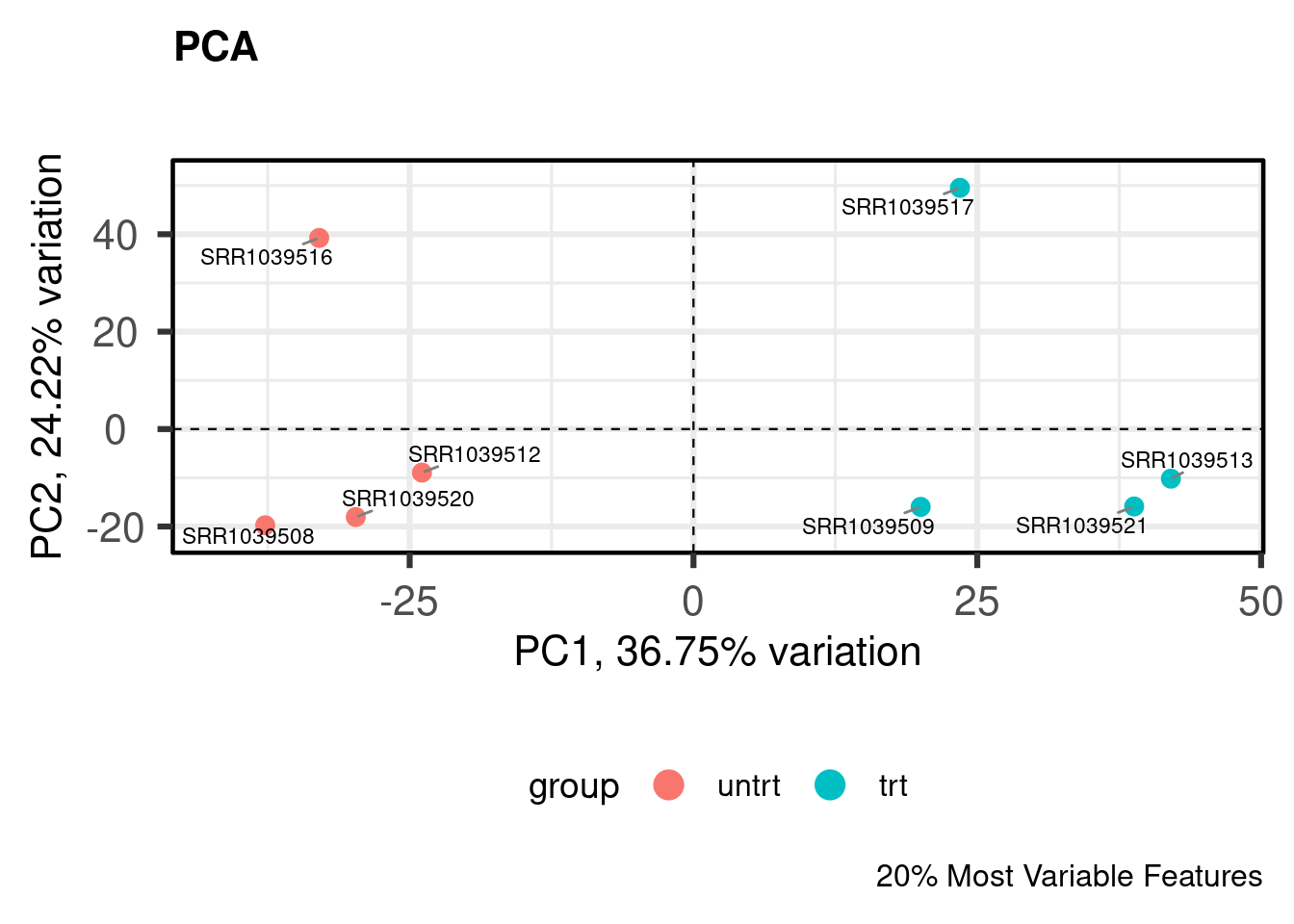
Assessing global scaling normalization assumptions
Most downstream differential expression testing methods apply a global scaling normalization factor to each library prior to DE testing. Applying these normalization factors when there are global expression differences can lead to spurious results. In typical experiments this is usually not a problem but when dealing with cancer or epigenetic drug treatment this can actually lead to many problems if not identified.
To identify potential violations of global scaling normalization I use the quantro R package. quantro uses two data driven approaches to assess the appropriateness of global scaling normalization. The first involves testing if the medians of the distributions differ between groups. These differences could indicate technical or real biological variation. The second test assesses the ratio of between group variability to within group variability using a permutation test similar to an ANOVA. If this value is large, it suggests global adjustment methods might not be appropriate.
library(quantro)
# Initialize multiple (8) cores for permutation testing
doParallel::registerDoParallel(cores = 8)
# Compute the qstat on the filtered libraries
qtest <- quantro(y$counts, groupFactor = y$samples$group, B = 500)Now we can assess the results. We can use anova() to test for differences in medians across groups. Here, they do not significantly differ.
anova(qtest)Analysis of Variance Table
Response: objectMedians
Df Sum Sq Mean Sq F value Pr(>F)
groupFactor 1 1984.5 1984.5 0.3813 0.5596
Residuals 6 31225.5 5204.2 We can also plot the results of the permutation test to see the between:within group ratios. Again, there are no large differences in this dataset suggesting that global scaling normalization such as TMM is appropriate.
quantroPlot(qtest)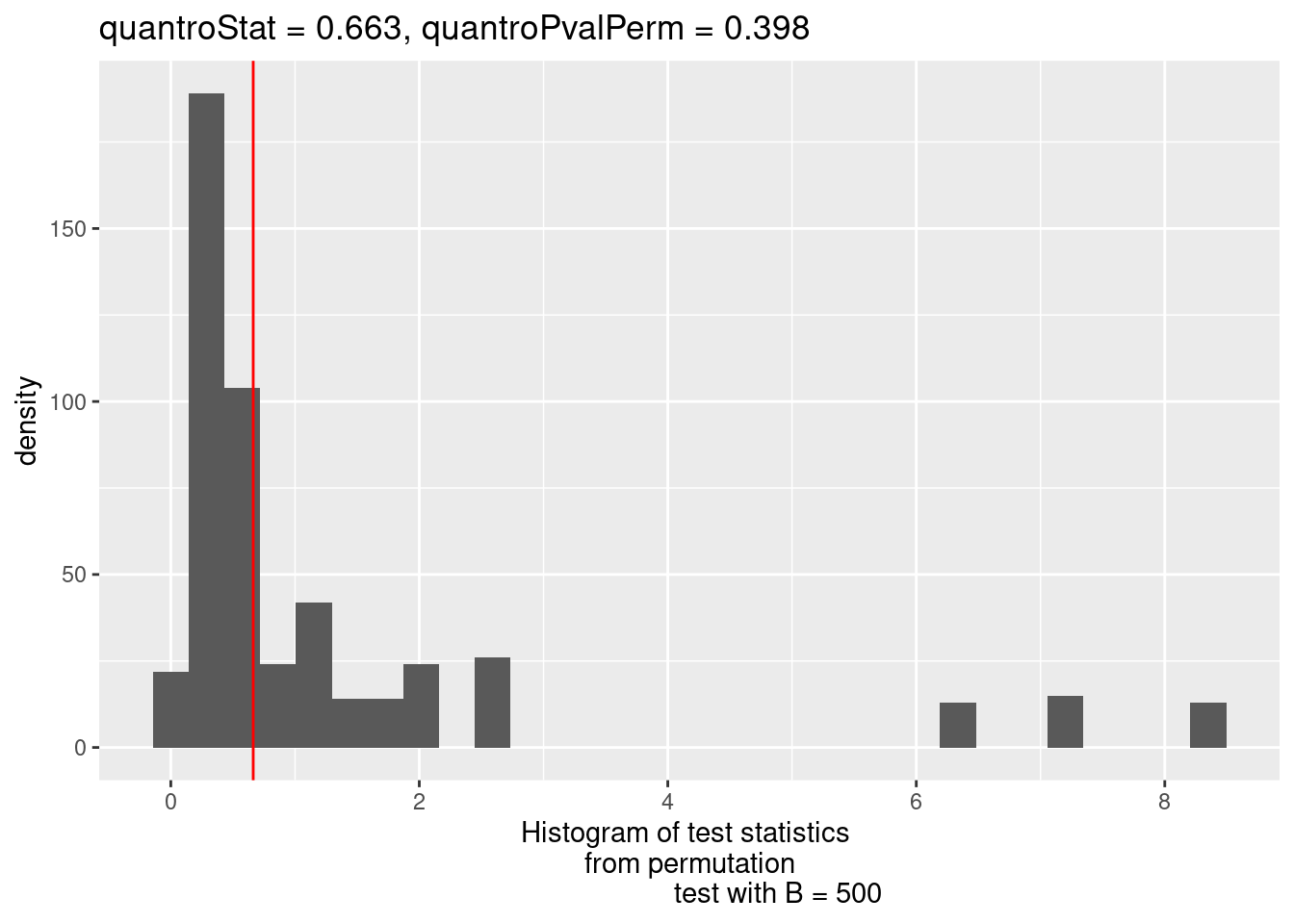
Differential expression testing with edgeR
After removing lowly expressed features and checking the assumptions of normalization we can perform downstream differential expression testing with edgeR. The edgeR manual contains a detailed explanation of all steps involved in differential expression testing.
In short, we need to specify the experimental design, estimate normalization factors, fit the models, and perform DE testing.
Creating the experimental design
Maybe the most important step in DE analysis is properly constructing a design matrix. The details of design matrices are outside of the scope of this tutorial but a good overview can be found here. Generally, your samples will fall nicely into several well defined groups, facilitating the use of a design matrix without an intercept e.g. design ~ model.matrix(~0 + group, ...). This kind of design matrix makes it relatively simple to construct contrasts that describe exactly what pairs of groups you want to compare.
Since this example experiment is simply comparing treatments to control samples we can model the differences in means by using a model with an intercept where the intercept is the mean of the control samples and the 2nd coefficient represents the differences in the treatment group.
# Model with intercept
design <- model.matrix(~group, data = y$samples)We can make an equivalent model and test without an intercept like so:
# A means model
design_no_intercept <- model.matrix(~ 0 + group, data = y$samples)
# Construct contrasts to test the difference in means between the groups
cm <- makeContrasts(
Treatment_vs_Control = grouptrt - groupuntrt,
levels = design_no_intercept
)The choice of which design is up to you. I typically use whatever is clearer for the experiment at hand. In this case, that is the model with an intercept.
Estimating normalization factors
We use edgeR to calculate trimmed mean of the M-value (TMM) normalization factors for each library. Then we compute the logCPMs usning the TMM scaling factors. At this point running plot_density2(lcpms), etc. is recommended.
# Estimate TMM normalization factors
y <- normLibSizes(y)
# Compute the log2 CPMs after normalization
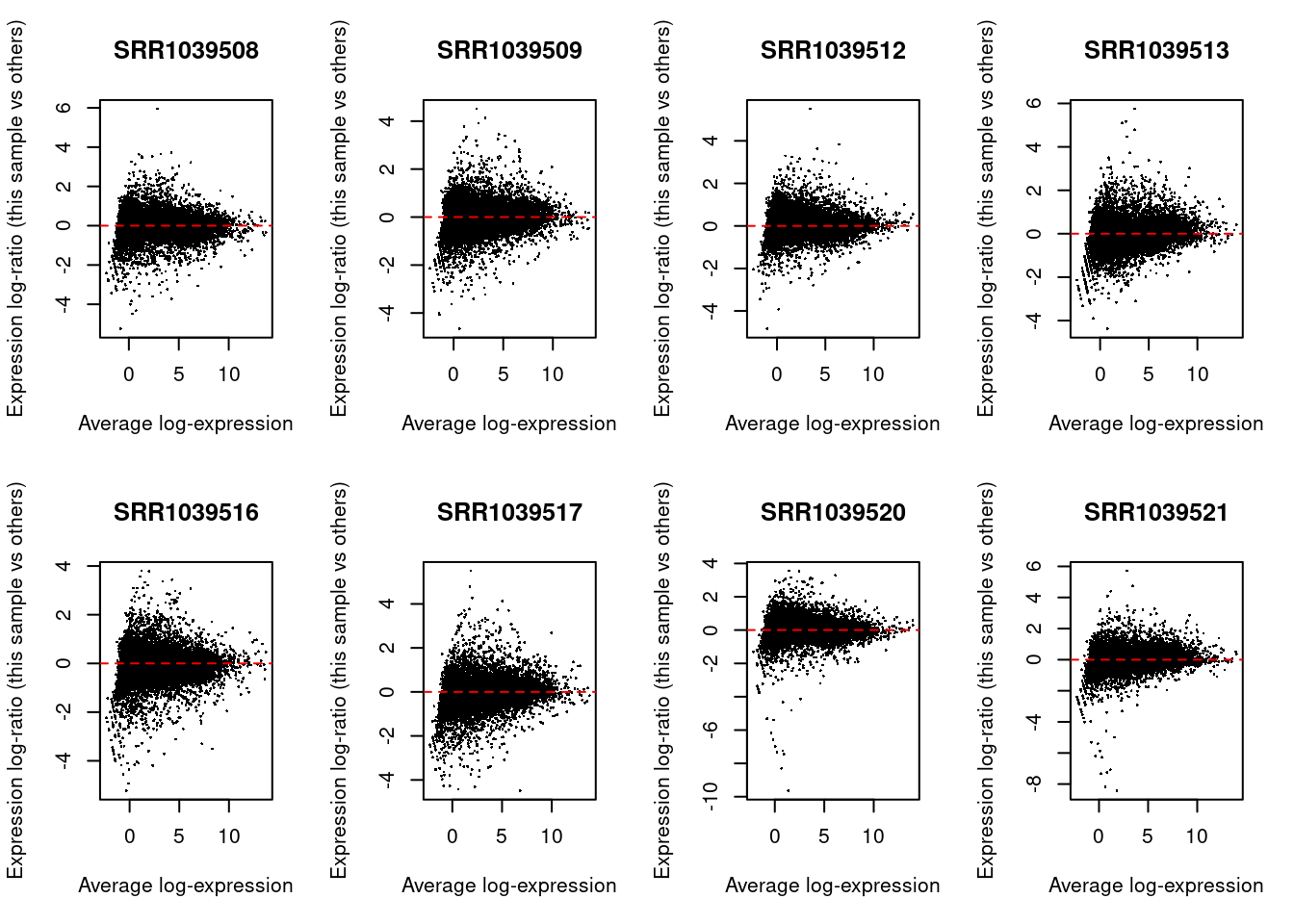
lcpms <- cpm(y, log = TRUE)We can check the normalization by creating MA plots for each library. The bulk of the data should be centered on zero without any obvious differences in the logFC as a function of average abundance.
par(mfrow = c(2, 4))
for (i in 1:ncol(y)) {
plotMD(lcpms, column = i)
abline(h = 0, lty = 2, col = "red2")
}
At this point it’s also a good idea to recheck the above plots using the normalized data
# RLE boxplots after normalization
plot_boxplot2(
lcpms,
y$samples,
fill_by = "group",
rle = TRUE,
show_outliers = FALSE,
plot_title = "Normalized Relative Log-Expression",
y_label = "RLE"
)
# Normalized library densities
plot_density2(
lcpms,
y$samples,
col_by = "group",
plot_title = "Normalized Library Density",
x_label = "logCPM"
)
# PCA
plotMDS(
lcpms,
pch = 16,
col = grp_pal[y$samples$group],
cex = 1.8,
gene.selection = "common"
)
legend("top", legend = levels(y$samples$group), col = grp_pal, pch = 16)What to do if global scaling normalization is violated?
Above I described testing for violations of global scaling normalization. So what should we do if these assumptions are violated and we don’t have a good set of control genes or spike-ins etc.?
If we believe that the differences we are observing are due to true biological phenomena (this is a big assumption) then we can try to apply a method such as smooth quantile normalization to the data using the qsmooth package.
Below I will show how to apply qsmooth to our filtered counts and then calculate offsets to be used in downstream DE analysis with edgeR. Please note this is not a benchmarked or ‘official’ workflow just a method that I have implemented based on reading forums and github issues.
library(qsmooth)
# Compute the smooth quantile factors
qs <- qsmooth(y$counts, group_factor = y$samples$group)
# Extract the qsmooth transformed data
qsd <- qsmoothData(qs)
# Calculate offsets to be used by edgeR in place of norm.factors
# Offsets are on the natural log scale.
# Add a small prior_count to avoid taking logs of zero
prior_count <- 0.1
offset <- log(y$counts + prior_count) - log(qsd + prior_count)
# Add the offset matrix to the edgeR object
y <- scaleOffset(y, offset)
# To create logCPM values with the offsets
lcpms <- cpm(y, offset = y$offset, log = TRUE)Fit the model
New in edgeR 4.0 is the ability to estimate dispersions while performing the model fitting step. I typically tend to ‘robustify’ the fit to outliers. NOTE: if you are familiar with the old edgeR workflow this step directly skips estimateDisp()
fit <- glmQLFit(y, design, robust = TRUE)Test for differential expression
Now that the models have been fit we can test for differential expression.
# Test the treatment vs control condition
qlf <- glmQLFTest(fit, coef = 2)Often it is more biologically relevant to give more weight to higher fold changes. This can be achieved using glmTreat(). NOTE do not use glmQLFTest() and then filter by fold-change - you destroy the FDR correction!
When testing against a fold-change we can use relatively modest values since the fold-change must exceed this threshold before being considered for significance. Values such as log2(1.2) or log2(1.5) work well in practice.
trt_vs_control_fc <- glmTreat(fit, coef = 2, lfc = log2(1.2))In any case, the results of the differential expression test can be extracted to a data.frame for downstream plotting with coriell::edger_to_df(). This function simply returns a data.frame of all results from the differential expression object in the same order as y. (i.e. topTags(..., n=Inf, sort.by="none"))
de_result <- edger_to_df(qlf)Plotting DE results
The two most common plots for differential expression analysis results are the volcano plot and the MA plot. Volcano plots display the negative log10 of the significance value on the y-axis vs the log2 fold-change on the x-axis. MA plots show the average expression of the gene on the x-axis vs the log2 fold-change of the gene on the y-axis. The coriell package includes functions for producing both.
library(patchwork)
# Create a volcano plot of the results
v <- plot_volcano(de_result, fdr = 0.05)
# Create and MA plot of the results
m <- plot_md(de_result, fdr = 0.05)
# Patch both plots together
(v | m) +
plot_annotation(title = "Treatment vs. Control") &
theme_coriell()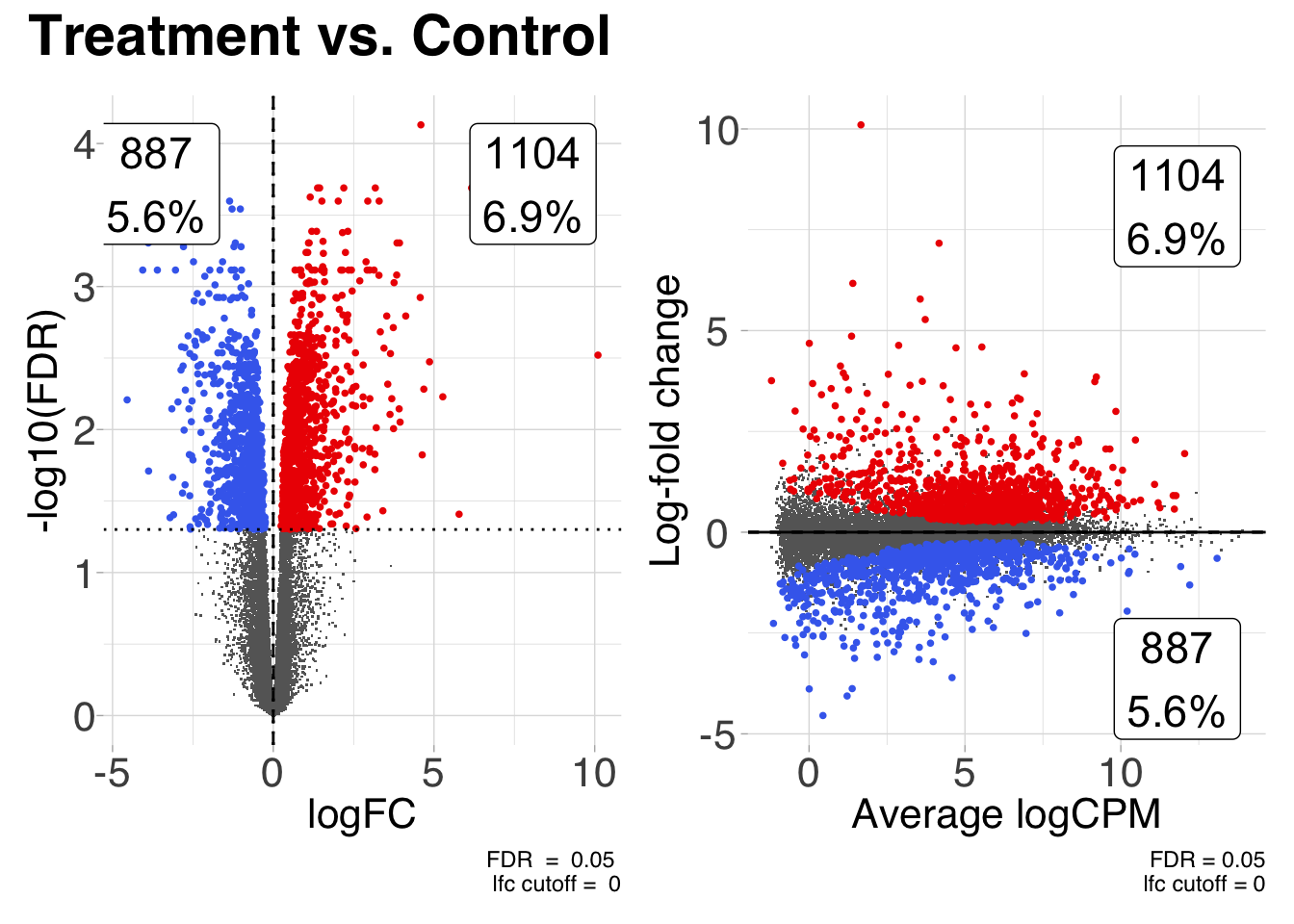
The coriell package also has a function for quickly producing heatmaps with nice defaults for RNA-seq. Sometimes it’s useful to show the heatmaps of the DE genes.
# Compute logCPM values after normalization
lcpm <- cpm(y, log = TRUE)
# Determine which of the genes in the result were differentially expressed
is_de <- de_result$FDR < 0.05
# Produce a heatmap from the DE genes
quickmap(
x = lcpm[is_de, ],
metadata = y$samples[, "group", drop = FALSE],
main = "Differentially Expressed Genes"
)
Competitive gene set testing with camera()
I’ve recently become aware of some of the problems with gene set enrichment analysis using the fgsea package. Following Gordon Smyth’s advice, I have switched all of my pipelines to using competitive gene set testing (when appropriate) in limma to avoid problems with correlated genes.
Below we use the msigdbr R package to retrieve HALLMARK gene sets and then use camera()` for gene set testing.
library(msigdbr)
# Get the HALLMARK gene set data
msigdb_hs <- msigdbr(species = "Homo sapiens", collection = "H")
# Split into list of gene names per HALLMARK pathway
msigdb_hs <- split(as.character(msigdb_hs$gene_symbol), msigdb_hs$gs_name)
# Convert the gene sets into lists of indeces for edgeR
idx <- ids2indices(gene.sets = msigdb_hs, identifiers = y$genes$gene_name)Perform gene set testing. Note here we can use camera() mroast(), or romer() depending on the hypothesis being tested. The above setup code provides valid input for all of the above functions.
See this comment from Aaron Lun describing the difference between camera() and roast(). For GSEA like hypothesis we can use romer()
roast()performs a self-contained gene set test, where it looks for any DE within the set of genes.camera()performs a competitive gene set test, where it compares the DE within the gene set to the DE outside of the gene set.
# NOTE: if you used the new edgeR 4.0 workflow you can add common dispersion
# needed by downstream plotting/gene set testing with:
y$common.dispersion <- fit$dispersion
# Use camera to perform competitive gene set testing
camera_result <- camera(y, idx, design, contrast = 2)
# Use mroast for rotational gene set testing - bump up number of rotations
mroast_result <- mroast(y, idx, design, contrast = 2, nrot = 1e4)
# Use romer for GSEA like hypothesis testing
romer_result <- romer(y, idx, design, contrast = 2)We can also perform a pre-ranked version of the camera test using cameraPR(). To use the pre-ranked version we need to create a ranking statistic. The suggestion from Gordon Smyth is to derive a z-statistic from the F-scores like so:
t_stat <- sign(de_result$logFC) * sqrt(de_result$`F`)
z <- zscoreT(t_stat, df = qlf$df.total)
# Name the stat vector with the gene names
names(z) <- de_result$gene_name
# Use the z-scores as the ranking stat for cameraPR
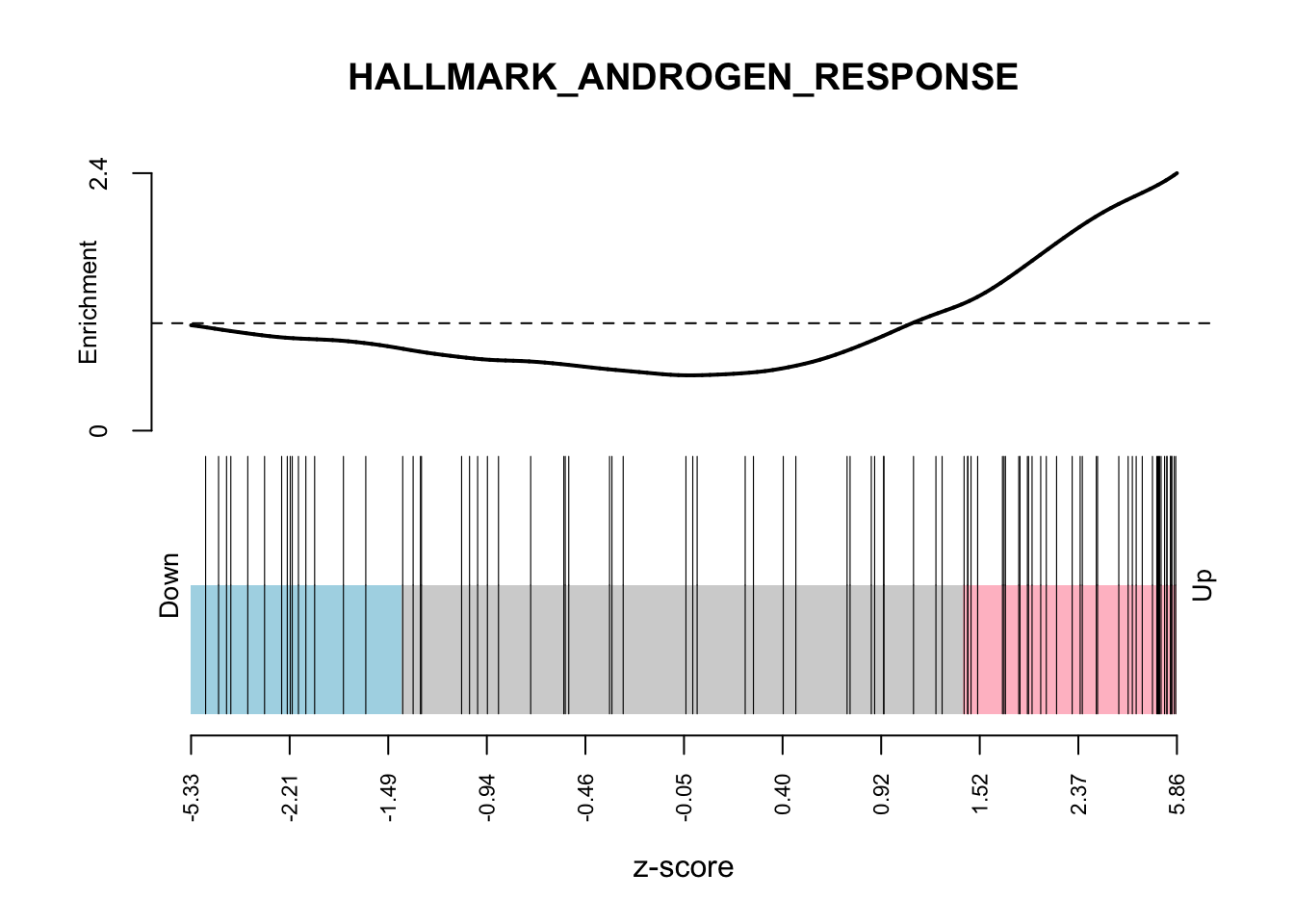
camera_pr_result <- cameraPR(z, idx)Another useful plot to show following gene set testing is a barcodeplot. We The barcodeplot displays the enrichment of a given signature for a ranked list of genes. The limma::barcodeplot() function allows us to easily create these plots for any of the gene sets of interest using any ranking stat of our choice.
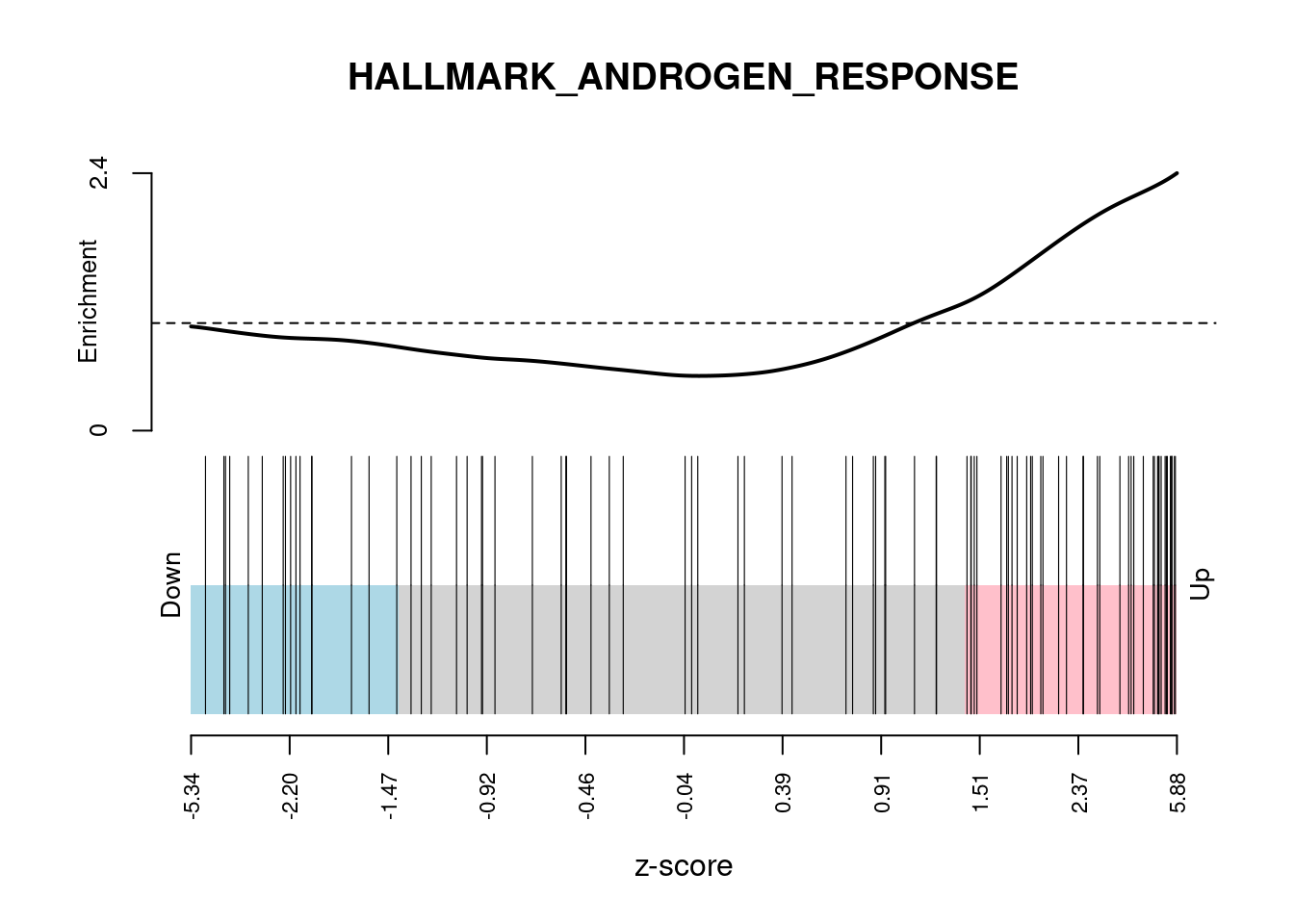
# Show barcodeplot using the z-scores
barcodeplot(
z,
index = idx[["HALLMARK_ANDROGEN_RESPONSE"]],
main = "HALLMARK_ANDROGEN_RESPONSE",
xlab = "z-score"
)
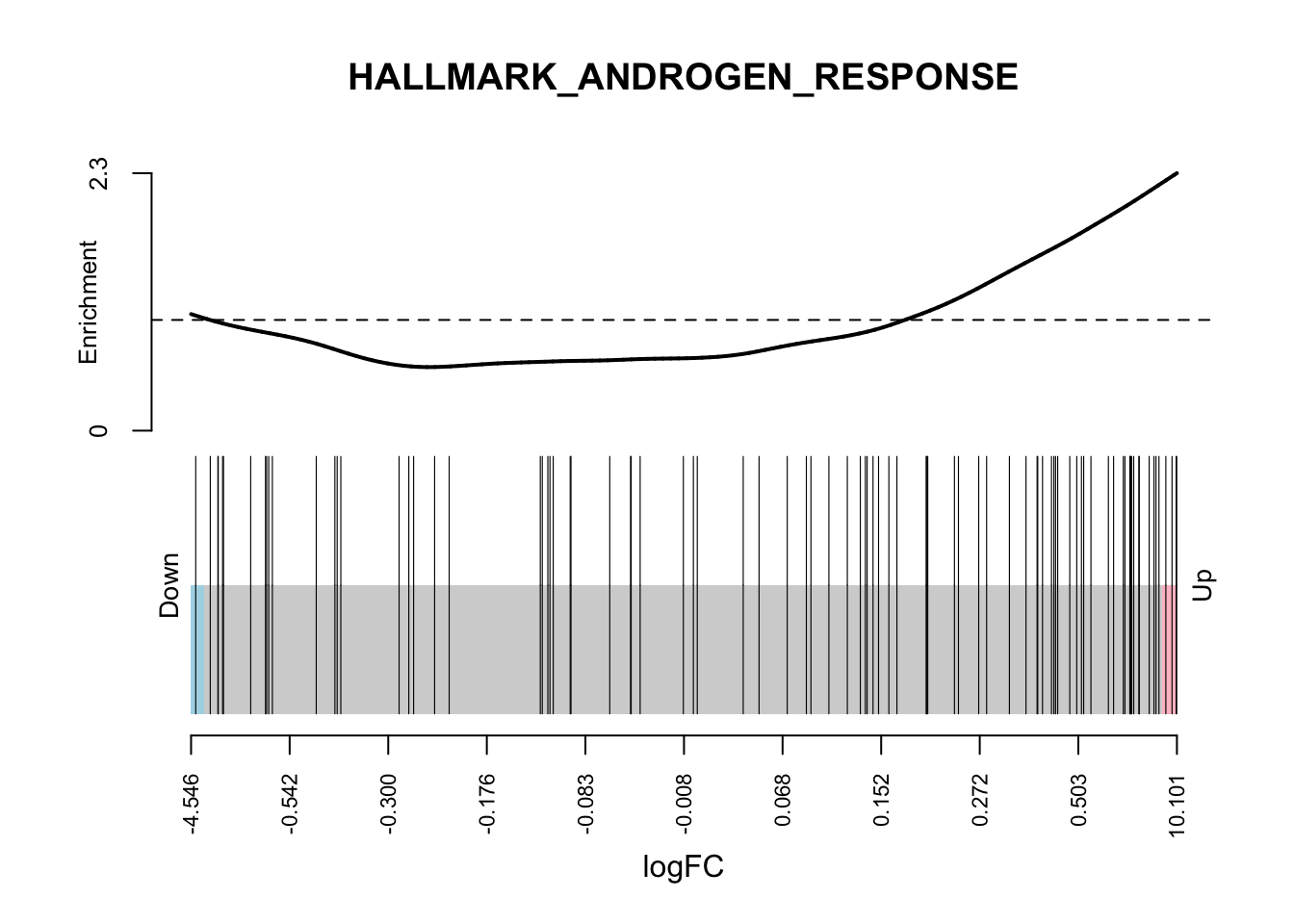
# Or you can use the logFC
barcodeplot(
de_result$logFC,
index = idx[["HALLMARK_ANDROGEN_RESPONSE"]],
main = "HALLMARK_ANDROGEN_RESPONSE",
xlab = "logFC"
)
We can also visualize the camera() results using an enrichment map from the TMSig package. To make the results conform to the expected input of the TMSig::enrichmap() function, we need to add a few new columns to the results data.frame.
library(TMSig)
# Add columns needed by TMSig::enrichmap()
camera_result$Pathway <- rownames(camera_result)
camera_result$Contrast <- "Treatment vs. Control"
camera_result$stat <- ifelse(camera_result$Direction == "Down", -1, 1)
# Finally, show the enrichment map for the top 15 results
enrichmap(
x = camera_result,
scale_by = "max",
n_top = 15,
plot_sig_only = FALSE,
set_column = "Pathway",
statistic_column = "stat",
contrast_column = "Contrast",
padj_column = "FDR",
padj_legend_title = "BH Adjusted\nP-Value",
padj_cutoff = 0.05
)
Gene ontology (GO) over-representation test
Over-representation testing can be performed with edgeR’s goana() and kegga() functions. These functions also enable adjusting for gene length bias by incorporating gene lengths as a covariate during testing. The only slightly annoying aspect to using these functions is that they use Entrez IDs as input and I typically use GENCODE / Ensembl Ids.
Computing gene lengths
If you do not have gene length information available, one way of deriving it is by computing the sum of the reduced exon lengths for each gene. This can be accomplished using a TxDb object or creating one directly from a GTF.
The annotation used in the airway package is from Ensembl v75 we can import the gtf as a txdb object in order to compute gene length information
library(txdbmaker)
# Download and create a txdb object from the ensembl GTF
url <- "https://ftp.ensembl.org/pub/release-75/gtf/homo_sapiens/Homo_sapiens.GRCh37.75.gtf.gz"
txdb <- makeTxDbFromGFF(url, format = "gtf")
# Extract exon features by gene id, create reduced features, sum the widths by gene
exons_by_gene <- exonsBy(txdb, by = "gene")
reduced_exon_lengths <- sum(width(reduce(exons_by_gene)))
names(reduced_exon_lengths) <- names(exons_by_gene)
# Add the length information back to the de_results
de_result$Length <- reduced_exon_lengths[de_result$gene_id]Converting from ENSEMBL Ids to Entrez Ids
If you have Ensembl Ids you’ll need to find the coresponding Entrez Id before proceeding with goana(). We can use the mapIds() function from the AnnotationDbi package and the Ensembl Org Db object to get this mapping. NOTE: the mapping is generally not one-to-one.
library(org.Hs.eg.db)
library(AnnotationDbi)
# Convert gene IDs to Entrez IDs
de_result$entrez_id <- mapIds(
org.Hs.eg.db,
keys = de_result$gene_id,
keytype = "ENSEMBL",
column = "ENTREZID"
)Now we have all of the ingredients to perform GO (or KEGG) over-representation analysis. First, we will need to create subsets for up and down-regulated genes. Then we can test for over-representation adjusting for gene length biases.
# Extract all assayed genes (that have entrez IDs) to be used as background
universe <- de_result$entrez_id
universe <- universe[!is.na(universe)]
# Extract the lengths for genes in the universe
lengths <- de_result$Length[match(universe, de_result$entrez_id)]
# Get Entrez Ids of up and down genes
up_genes <- de_result[de_result$logFC > 0 & de_result$FDR < 0.05, "entrez_id"]
down_genes <- de_result[de_result$logFC < 0 & de_result$FDR < 0.05, "entrez_id"]
up_genes <- up_genes[!is.na(up_genes)]
down_genes <- down_genes[!is.na(down_genes)]Perform GO over-representation testing
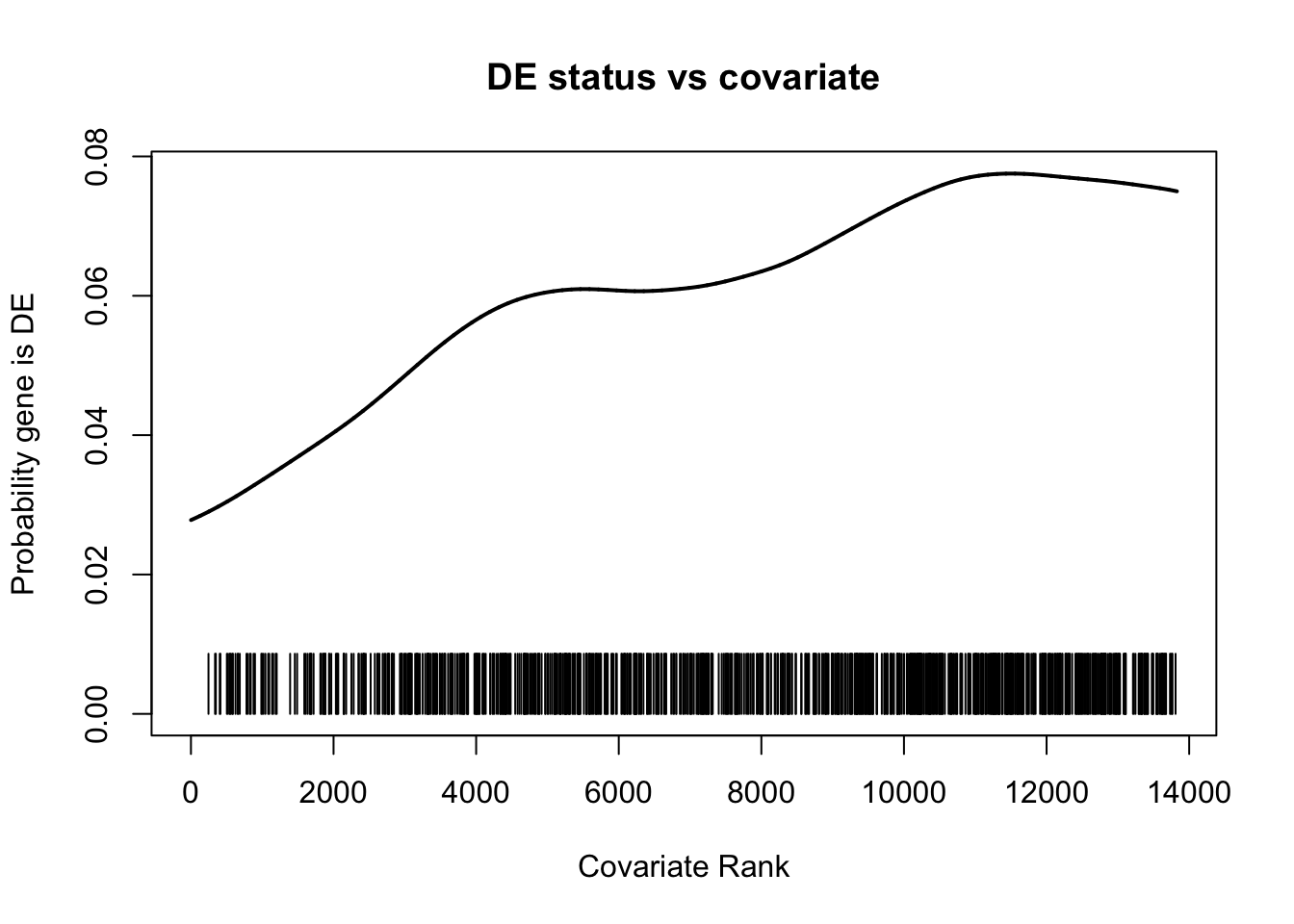
up_go <- goana(
up_genes,
universe = universe,
species = "Hs",
null.prob = NULL,
covariate = lengths,
plot = TRUE
)
down_go <- goana(
down_genes,
universe = universe,
species = "Hs",
null.prob = NULL,
covariate = lengths,
plot = TRUE
)
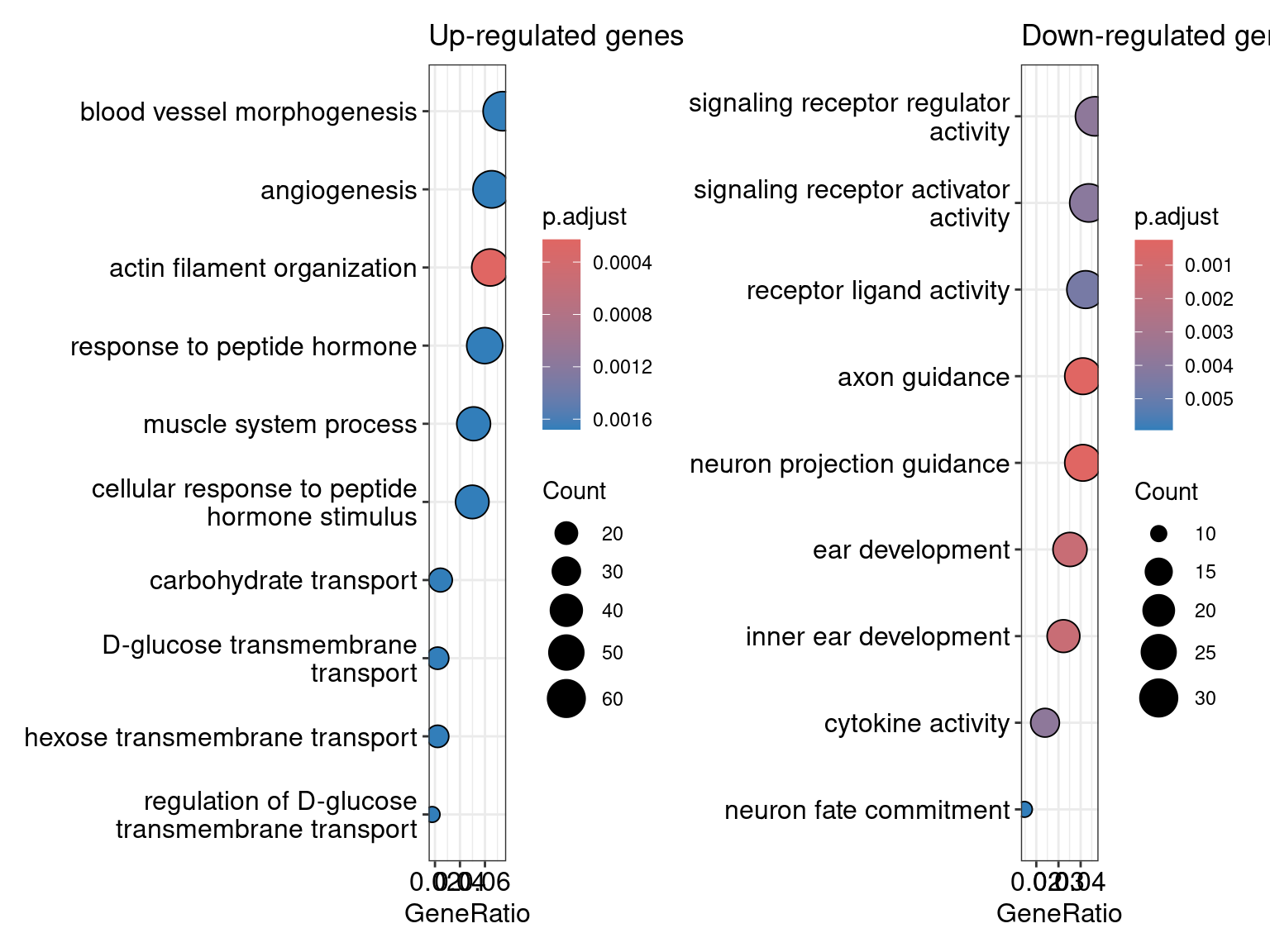
We can also plot these results after creating a simple function. Below I am plotting the top GO results from biological processes (BP)
library(ggplot2)
plot_dotplot <- function(df, n = 15, term = "Term") {
df <- df[order(df$P.DE), ]
df <- head(df, n = n)
df$prop_in_set <- df$N / df$DE
ggplot(df, aes(x = -log10(P.DE), y = reorder(df[[term]], -P.DE))) +
geom_point(aes(size = prop_in_set, color = -log10(P.DE))) +
scale_color_viridis_c() +
labs(
x = "-log10(P-value)",
y = NULL,
color = "-log10(P-value)",
size = "Prop. Genes in Set"
) +
theme_classic()
}
d1 <- plot_dotplot(subset(up_go, Ont == "BP")) +
labs(title = "Up-regulated Genes")
d2 <- plot_dotplot(subset(down_go, Ont == "BP")) +
labs(title = "Down-regulated Genes")
(d1 | d2) + plot_annotation(title = "Top GO Terms")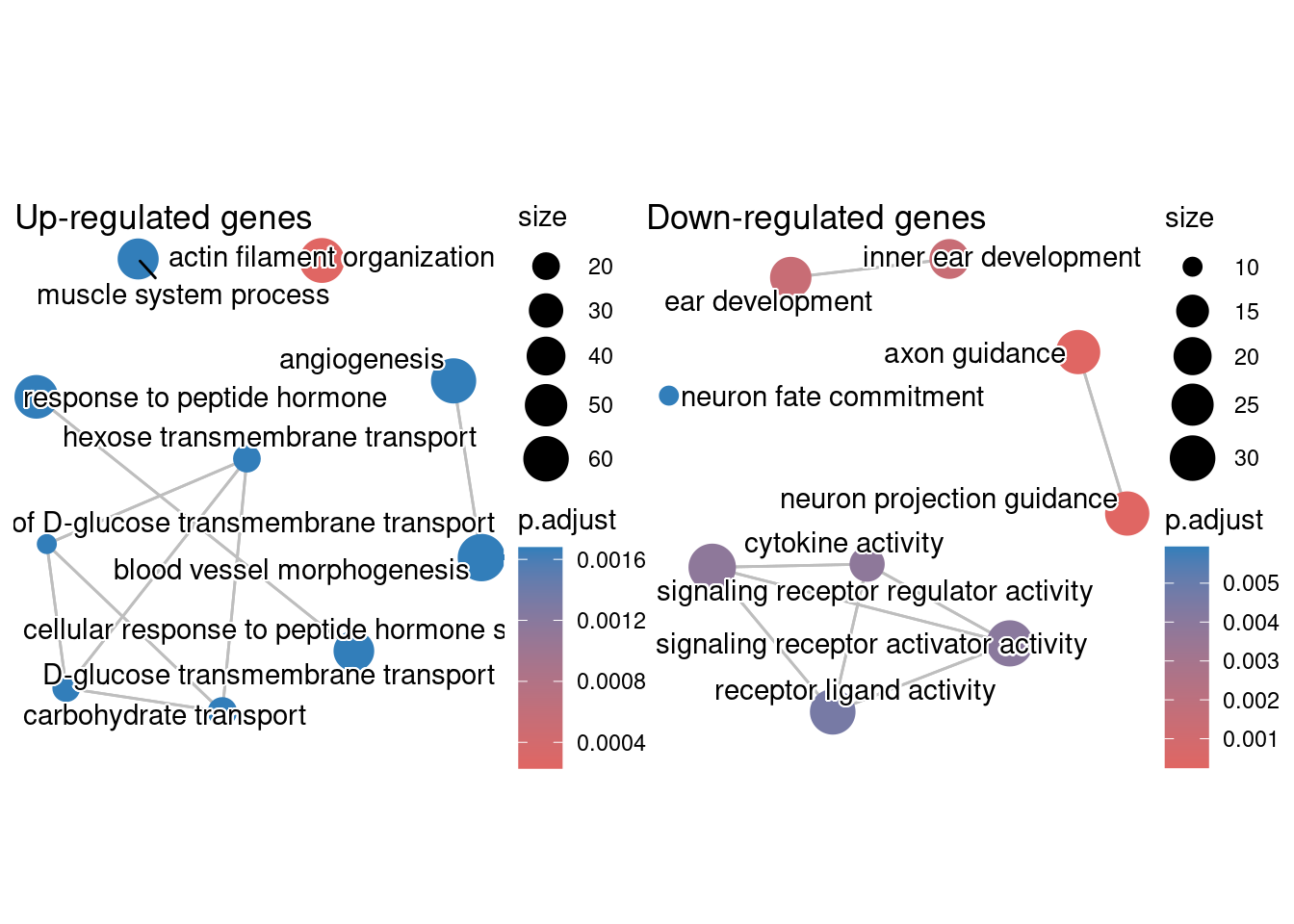
Session Info
sessionInfo()R version 4.5.1 (2025-06-13)
Platform: x86_64-apple-darwin20
Running under: macOS Sequoia 15.7.4
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.5-x86_64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.5-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
locale:
[1] C
time zone: America/New_York
tzcode source: internal
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] ggplot2_4.0.1 org.Hs.eg.db_3.21.0
[3] txdbmaker_1.4.2 GenomicFeatures_1.60.0
[5] AnnotationDbi_1.70.0 TMSig_1.2.0
[7] msigdbr_25.1.1 patchwork_1.3.2
[9] quantro_1.42.0 coriell_0.18.0
[11] edgeR_4.6.3 limma_3.64.3
[13] airway_1.28.0 SummarizedExperiment_1.38.1
[15] Biobase_2.68.0 GenomicRanges_1.60.0
[17] GenomeInfoDb_1.44.3 IRanges_2.42.0
[19] S4Vectors_0.46.0 BiocGenerics_0.54.1
[21] generics_0.1.4 MatrixGenerics_1.20.0
[23] matrixStats_1.5.0
loaded via a namespace (and not attached):
[1] splines_4.5.1 BiocIO_1.18.0
[3] filelock_1.0.3 bitops_1.0-9
[5] BiasedUrn_2.0.12 tibble_3.3.1
[7] preprocessCore_1.70.0 graph_1.86.0
[9] XML_3.99-0.20 httr2_1.2.2
[11] lifecycle_1.0.5 doParallel_1.0.17
[13] lattice_0.22-7 MASS_7.3-65
[15] base64_2.0.2 scrime_1.3.5
[17] magrittr_2.0.4 minfi_1.54.1
[19] rmarkdown_2.30 yaml_2.3.12
[21] otel_0.2.0 doRNG_1.8.6.2
[23] askpass_1.2.1 DBI_1.2.3
[25] RColorBrewer_1.1-3 abind_1.4-8
[27] quadprog_1.5-8 purrr_1.2.1
[29] RCurl_1.98-1.17 rappdirs_0.3.3
[31] circlize_0.4.17 GenomeInfoDbData_1.2.14
[33] rentrez_1.2.4 genefilter_1.90.0
[35] pheatmap_1.0.13 annotate_1.86.1
[37] DelayedMatrixStats_1.30.0 codetools_0.2-20
[39] DelayedArray_0.34.1 xml2_1.5.1
[41] tidyselect_1.2.1 shape_1.4.6.1
[43] UCSC.utils_1.4.0 farver_2.1.2
[45] beanplot_1.3.1 BiocFileCache_2.16.2
[47] illuminaio_0.50.0 GenomicAlignments_1.44.0
[49] jsonlite_2.0.0 GetoptLong_1.1.0
[51] multtest_2.64.0 survival_3.8-3
[53] iterators_1.0.14 foreach_1.5.2
[55] progress_1.2.3 tools_4.5.1
[57] Rcpp_1.1.1 glue_1.8.0
[59] SparseArray_1.8.1 xfun_0.55
[61] dplyr_1.1.4 HDF5Array_1.36.0
[63] withr_3.0.2 fastmap_1.2.0
[65] rhdf5filters_1.20.0 openssl_2.3.4
[67] digest_0.6.39 R6_2.6.1
[69] colorspace_2.1-2 GO.db_3.21.0
[71] biomaRt_2.64.0 RSQLite_2.4.5
[73] h5mread_1.0.1 tidyr_1.3.2
[75] data.table_1.18.0 rtracklayer_1.68.0
[77] prettyunits_1.2.0 httr_1.4.7
[79] htmlwidgets_1.6.4 S4Arrays_1.8.1
[81] pkgconfig_2.0.3 gtable_0.3.6
[83] blob_1.2.4 ComplexHeatmap_2.24.1
[85] S7_0.2.1 siggenes_1.82.0
[87] XVector_0.48.0 htmltools_0.5.9
[89] GSEABase_1.70.1 clue_0.3-66
[91] scales_1.4.0 png_0.1-8
[93] knitr_1.51 tzdb_0.5.0
[95] rjson_0.2.23 nlme_3.1-168
[97] curl_7.0.0 bumphunter_1.50.0
[99] cachem_1.1.0 rhdf5_2.52.1
[101] GlobalOptions_0.1.3 stringr_1.6.0
[103] KernSmooth_2.23-26 parallel_4.5.1
[105] restfulr_0.0.16 GEOquery_2.76.0
[107] pillar_1.11.1 grid_4.5.1
[109] reshape_0.8.10 vctrs_0.6.5
[111] dbplyr_2.5.1 xtable_1.8-4
[113] cluster_2.1.8.1 evaluate_1.0.5
[115] readr_2.1.6 cli_3.6.5
[117] locfit_1.5-9.12 compiler_4.5.1
[119] Rsamtools_2.24.1 rlang_1.1.7
[121] crayon_1.5.3 rngtools_1.5.2
[123] labeling_0.4.3 nor1mix_1.3-3
[125] mclust_6.1.2 plyr_1.8.9
[127] stringi_1.8.7 viridisLite_0.4.2
[129] BiocParallel_1.42.2 assertthat_0.2.1
[131] babelgene_22.9 Biostrings_2.76.0
[133] Matrix_1.7-4 hms_1.1.4
[135] sparseMatrixStats_1.20.0 bit64_4.6.0-1
[137] Rhdf5lib_1.30.0 KEGGREST_1.48.1
[139] statmod_1.5.1 memoise_2.0.1
[141] bit_4.6.0